

NVIDIA RTX PC 與 DGX Spark 加速由 Hermes 解鎖的自主進化 AI 智能體
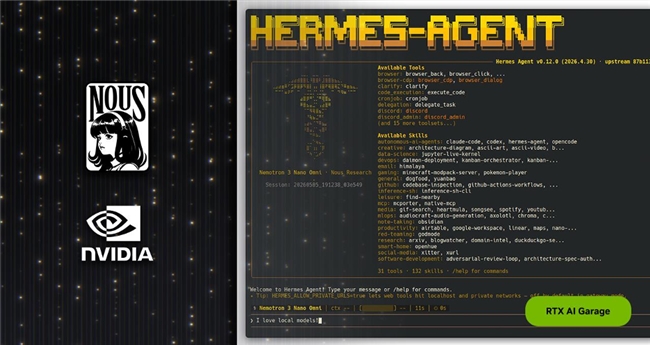
代理式 AI 正在改變用戶完成工作的方式。繼 OpenClaw 取得成功之后,社區正積極擁抱新的開源代理式框架。最新框架是 Hermes Agent,在不到 3 個月內突破 140,000 GitHub 星標。截至上周,根據 OpenRouter 的數據,它已成為全球使用量最高的智能體。
Nous Research 開發的 Hermes 專為可靠性與自我改進而設計,這兩項特質一直以來都很難在智能體中實現。Hermes 特意不綁定提供商和模型,并針對始終在線的本地使用場景進行優化,因此 NVIDIA RTX PC、NVIDIA RTX PRO 工作站和 NVIDIA DGX Spark 成為全天候全速運行它的理想硬件。
Qwen 3.6 是阿里巴巴推出的新一代高性能開放權重大語言模型(LLM)系列,非常適合運行 Hermes 這樣的本地智能體。Qwen 3.6 27B 和 35B 參數模型的表現超過了上一代 120B 和 400B 參數模型,并可在 NVIDIA RTX 與 DGX Spark 上運行,為代理式 AI 提供加速。
Hermes:加速本地?AI?智能體能力
與其他熱門智能體一樣,Hermes 可集成消息應用,訪問本地文件和應用,并全天候 24 小時運行。但以下 4 項突出能力讓它脫穎而出:
● 自主進化技能:Hermes 會編寫并改進自己的技能。每當智能體遇到復雜任務或收到反饋時,它都會將學習成果保存為技能,從而隨著時間推移持續適應和改進。
● 受控子智能體:Hermes 將子智能體視為面向子任務的,生命周期很短的單獨工作單元,并為其配備專用的上下文和工具集。這可以讓任務組織更清晰,減少智能體混淆,并讓 Hermes 以更小的上下文窗口運行,非常適合本地模型。
● 可靠性源于設計:Nous Research 會整理并壓力測試 Hermes 隨附的每一項技能、工具和插件。即使搭配 30B 參數級別的本地模型,Hermes 也能開箱即用,無需像大多數其他智能體框架那樣持續調試。
● 同一模型,更好結果:開發者在不同框架中使用相同模型進行比較時,Hermes 始終展現出更好的結果。差異來自框架本身:Hermes 是一個主動編排層,而不是輕量封裝器,可支持持久運行的本地端側智能體,而非逐項任務執行。
Hermes 智能體和底層 LLM 都為本地運行而構建,這意味著硬件質量將直接決定用戶體驗質量。NVIDIA RTX GPU 正是為這類工作負載而打造。
Qwen 3.6:在本地提供數據中心級智能
最新 Qwen 3.6 模型基于廣受認可的 Qwen 3.5 系列打造,為本地 AI 智能體帶來又一次飛躍。全新 Qwen 3.6 35B 模型可在約 20GB 內存上運行,同時生成結果超越需要 70GB 以上內存的 120B 參數模型。
Qwen 3.6 27B 是一款新的稠密模型,擁有更多活躍參數,在僅為 Qwen 3.5 397B 等 400B 參數模型 1/16 大小的同時,達到相似的準確率。高端 RTX GPU 可為該模型提供實現高速體驗所需的計算能力。
這些模型非常適合 Hermes 這樣的本地智能體,而 NVIDIA GPU 和 DGX Spark 是運行它們的最快方式。NVIDIA Tensor Cores 可加速 AI 推理,帶來更高吞吐量和更低延遲,讓 Hermes 能夠在數秒而非數分鐘內完成多步驟任務,或改進自身的一項技能。
DGX Spark:始終在線的代理式計算機
Hermes 這樣的智能體專為持續運行而構建,可以響應請求、規劃多步驟任務、自主執行并自我改進。NVIDIA DGX Spark 是理想搭檔,它是一臺緊湊、高效的獨立設備,專為持續全天候代理式工作流而打造。
128GB 統一內存和 1 petaFLOP AI 性能讓 NVIDIA DGX Spark 可全天運行 120B 參數混合專家模型。而全新 Qwen 3.6 35B 模型以更精簡的占用空間提供同等智能,不僅運行速度更快,還讓用戶有能力運行并發工作負載。
要最大限度提升性能并簡化使用體驗,請閱讀 Hermes DGX Spark Playbook。歡迎注冊 NVIDIA“Build It Yourself”代理式 AI 系列即將舉辦的實踐課程,了解如何使用 NemoClaw 和 OpenShell 構建自主 AI 智能體。
NVIDIA DGX Spark 現已可通過 NVIDIA 制造合作伙伴訂購,相關信息請查看市場頁面。
開始在?NVIDIA?硬件上使用?Hermes
在 NVIDIA 硬件上本地運行 Hermes 非常簡單。
訪問 Hermes GitHub 代碼庫即可開始使用并將其與用戶偏好的本地模型和運行時搭配,并通過 llama.cpp、LM Studio 或 Ollama 運行 Qwen 3.6 以搭配 Hermes。Hermes Agent 原生支持 LM Studio 和 Ollama,為本地智能體提供最簡單的上手路徑。
無論是探索個人智能體前沿的本地 AI 愛好者,還是為自身工作流構建本地工具的開發者,NVIDIA 硬件上的 Hermes 都能提供獨特強大且可靠的基礎。
敬請關注 RTX AI Garage,了解針對 NVIDIA RTX 硬件優化的最新開放模型和智能體的更多更新。
#別錯過:NVIDIA RTX AI Garage?最新動態
NVIDIA RTX PRO GPU?在運行 Qwen 3.6 模型與 llama.cpp 時,可實現最高 3 倍更快的 token 生成速度。它可為本地 AI 提供所需的實時響應能力,讓智能體處理多步驟任務并改進自身技能,從而保持工作流順暢無縫。
Google Gemma 4 26B?和?31B?模型現已推出?NVFP4 checkpoint,可在 NVIDIA Blackwell GPU 上實現更快性能。將 NVFP4 checkpoint與 Google 全新 Multi-Token Prediction 草稿模型搭配使用,可在相同輸出質量下實現最高 3 倍更快推理,讓前沿級推理能夠在 NVIDIA GPU 上本地運行。
Mistral Medium 3.5?版已于 4月發布,包含與 llama.cpp 和 Ollama 的兼容性更新,使用戶能夠在 NVIDIA RTX PRO 和 DGX Spark 系統上運行。
NVIDIA?最近推出了?NVIDIA?NemoClaw,這是一個可通過增強安全性和支持本地模型的開源堆棧,在 NVIDIA 設備上優化 OpenClaw 體驗。NemoClaw 現已支持 Windows Subsystem for Linux(WSL2),為微軟平臺上的愛好者和開發者帶來支持。開始在 DGX Spark 上使用 NemoClaw,請查看 Playbook。
NVIDIA RTX AI PC 的相關信息請關注微博、抖音及嗶哩嗶哩官方賬號。
軟件產品信息請查看聲明。
關于NVIDIA
NVIDIA (NASDAQ: NVDA) 是加速計算領域的全球領導者。
# # #
媒體咨詢:
Jade Li
NVIDIA GeForce, AI PC, DGX Spark PR
郵箱:jadli@nvidia.com
關注我們


